Master: Introducing the component coreference resolution task for requirement specification
Abstract
Consistent terminology is important for successful communication between two parties. If two parties do not agree on a common term for a component in their project, the resulting inconsistency leads to confusion and misunderstandings. In NLP this type of terminological inconsistency is called coreference since there are multiple terms that refer to a common entity. However, a pronoun that refers to its noun is also considered a coreferences. Our goal is to find coreferences among project components only. Thus, in this thesis, we introduce the novel term Component Coreference Resolution (CCR) to differentiate our task from other coreference resolution tasks. In addition, we propose a pipeline to automatically find component coreferences to aid authors in maintaining a consistent terminology. This is especially relevant if authors from different backgrounds work on shared documents as is the case in requirements engineering. To evaluate our pipeline, we manually constructed a test dataset based on public project requirement collections. This allowed us to control the number of coreferences in the test set precisely.
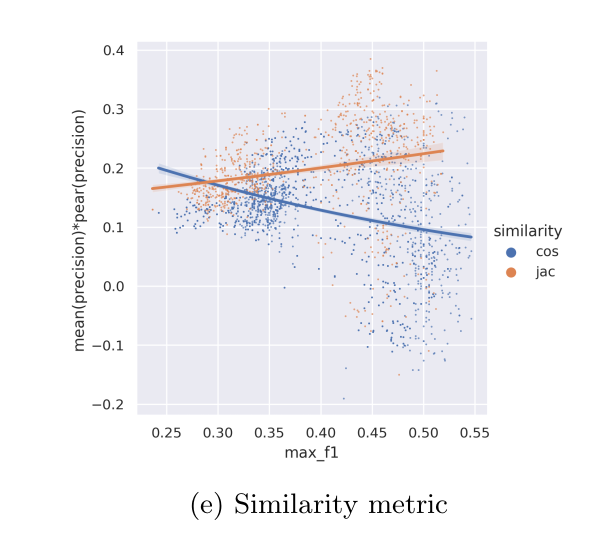
Our proposed pipeline is build on word vectors. These vectors attempt to capture the meaning of a word as a vector in a high dimensional vector space. For the CCR pipeline we explore three different word embedding models. To adopt publicly available weights for these models to the domain of the test set, we use unsupervised fine-training. Many terms are not single words but rather a phrase. To combine the individual vectors of the multiple words into a single phrase vector, we then systematically explore different phrase-, layer- and subword-pooling strategies. These pooling operations create a phrase vector with uniform length for any input phrase regardless of its length. Finally, to determine if two vectors are coreferent, we compare the resulting phrase vectors. For the comparison, we test cosine-similarity, Jaccard-Index and DynaMax.
During evaluation, we choose to place high emphasize on precision and its correlation to the underlying similarity score. This ensures that our results can be ranked by their similarity. We found that the Jaccard-Index significantly outperforms the generally recommend cosine similarity. Further, we contribute additional evidence that domain fine-trained models can outperform generalized supervised models.